To be relevant to more programming languages, this article only considers mocking interfaces as a means for software testing.
If the below contains notions and concepts that are unknown to you, I suggest that you read the rest of the article and then come back and read this section again.
After publishing this article, November 7th 2020, Robert C. Martin himself commented on it on Slack. The following is an excerpt from that comment.
Robert C. Martin also touched on that it's up to the architect to decide whether you need a Controller or Presenter. From that I conclude that the constituents of the Interface Adapters layer is not to be taken as a fixed set of objects that must always be there, instead, as a really good default.
- The Interface Adapters layer. This layer contains the code that adapts whatever delivery mechanisms (the web, databases etc) the application is using to the application business rules layer. The delivery mechanisms belong in the final layer which is the Frameworks and Drivers layer. In other words, the Interface Adapters layer acts as an adapter between the delivery mechanisms and the business functions defined in the enterprise and application business rules layers. In practice it contains implementations of the interfaces defined in the application business rules layer and whichever Data Transfer Objects needed to pass data to the Frameworks and Drivers layer.
Please note that no source code dependency is allowed to exist to the Frameworks and Drivers layer due to the dependency rule.
- The Frameworks and Drivers layer. This layer contains the code that glues together whatever framework the application is using with the Interface Adapters layer. It's in this layer that e.g. a controller in a MVC application is implemented since it's a part of a delivery mechanism, or e.g. Hibernate entities.
How to call code in a different layer without dependencies
For any arbitrary two layers A and B respectively, how can we accomplish that code in layer B should be able to invoke code in layer A without any source code dependency to layer A? It sounds like mission impossible, right?
This is nonetheless achievable by means of dynamic polymorphism i.e. by the use of interfaces. In the following figure class B has a "has-a" relationship to the interface Service. Since the latter is an interface it's not known at compile-time which class method will be invoked upon calling the interface's method. This is determined at run-time. In the example below the class Service Implementation implements the interface. This boils down to that the source code dependency (at compile-time) will be the inverse of the flow of control (at run-time).
The flow of control is the order in which the code statements are executed.
For example, at run-time when class B invokes Service, the statements in the method belonging to the Service Implementation will be executed and thus the direction of the flow of control is the opposite of the direction of the source code dependency.
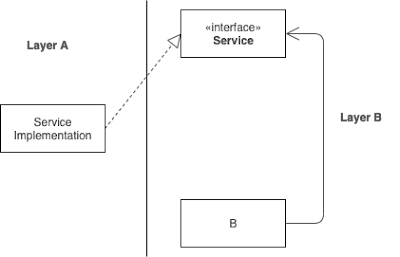 |
Figure 3. The flow of control is the inverse of the source code dependency
|
What if the methods declared by the interface Service require arguments of other than primitive types such as integers, booleans etc? Where should they be implemented?
Since it's not allowed for class B to have any source code dependencies to Layer A in this example, they have to be implemented in Layer B. Such an implementation is illustrated in the following figure.
 |
Figure 4. Data Transfer Objects are used to transfer data between layers
|
It's now possible for class B to pass data to Service Implementation in Layer A by using the class DTO. The general term for a class that solely exists to pass data to another class is called a Data Transfer Object. DTOs can also be used to return data to class B from Layer A.
Now it should be clear how any class in a layer can invoke code in another layer without having source code dependencies. This is how the higher-level layers in Clean Architecture can be without source code dependencies to the lower-level layers while at the same time be calling code in them at run-time.
Common pitfalls and misconceptions
The potential misdirection by a widespread image
The below image, created by Robert C. Martin, is probably familiar for those acquainted with Clean Architecture. I believe it to be the one that many people base their implementation attempts on and in my opinion the one image that is causing much confusion. If one is not careful, it's easy to start deriving which objects belong to what code layer, when in fact it's impossible to do so, since the objects are grouped by component, not by layer. Another problem with the below image is that the exact component boundaries are not clear. For example, do the Controller, Presenter, View Model, Entity Gateway Implementation and Database APIs all belong to the same component?
 |
Figure 5. Simplified Clean Architecture implementation
|
In the later section Clean Architecture in Practice I offer my take on a Clean Architecture implementation, which is presented in an object-by-layer layout.
The Controller confusion
In my opinion, the
Controller object is unfortunately named since it's one of the most common reasons for confusion amongst those that try to implement
Clean Architecture. Because of its name, by default people assume the
Controller object to be the same as a framework controller such as a class annotated with
@Controller or
@RestController in a Spring project. Nevertheless, this is not correct if you want to implement a strict
Clean Architecture. Such a controller belongs in the
Frameworks & Drivers layer. If the
Controller object were a framework controller then what would there be in the
Frameworks & Drivers layer, that's right, nothing.
Henceforth, a Controller written in italics and capitalised, refers to a Clean Architecture Controller in the Interface Adapters layer. An uncapitalised controller refers to a controller in the Frameworks & Drivers layer.
The flow of control confusion
In some of the implementations you can find online there seems to be a bit of confusion regarding the flow of control. There are quite a few implementations where a framework controller calls the interactor. This in itself is the first flow of control problem, since it's not according to Clean Architecture. See the previous section The Controller confusion. Then the interactor returns a Response Model, which would mean that there would have to be an association from the controller to the Response Model as well. The controller then supplies the Response Model as an argument to the Presenter. Again, this association from the controller to the Presenter shouldn't exist.
The correct flow of control is given below.
- Code from the lowest level layer i.e. the Frameworks & Drivers layer calls the Controller object.
- The Controller builds the Request Model and invokes the Interactor using this as an argument.
- The Interactor does its dance with the Entities and Gateway interfaces and builds a Response Model which it supplies the Presenter as an argument, by means of the Output Boundary interface.
- The Presenter converts the Response Model into a View Model object and that's it. It doesn't invoke the View, it just returns nothing, upon which the Interactor returns nothing and likewise the Controller returns nothing to the calling code in the Frameworks & Drivers layer. Please see Figure 5 to verify that there's no association from the Presenter to the View.
The Entities are Hibernate Entities confusion
This is another example of how unfortunate naming can cause a lot of confusion. Entities in Clean Architecture are not the same as entities in Hibernate. The latter are normally classes annotated with special Hibernate-specific annotations. Furthermore, they also have an ID-field which usually is either a 32-bit or 64-bit integer or a UUID. This field's type is dependent on the persistence implementation. For example, in MongoDB a UUID is used to uniquely identify a document where as in PostgreSql it's possible to identify rows using a number of different types, UUID is one of them. Entities in Clean Architecture on the other hand, can't have any source code dependencies outside of the Entities layer, which makes it impossible for them to be Hibernate Entities since having annotations also means import statements that go beyond the Entities layer which breaks the dependency rule. If it simplifies the code to also have ID-fields in the Entities that are of types found in the standard library, then that's ok, since it doesn't break the dependency rule, but it doesn't quite feel "clean" to have implementation-specific dependencies leak into the most sacred of all layers, which should be free of such details.
The View is a part of the Interface Adapters layer confusion
It's easy to think that the View is a part of the Interface Adapters layer, but this isn't possible since that would make the Interface Adapters layer aware of implementation details such as static or dynamic HTML pages, RESTful JSON/XML responses etc. The View must thus belong to the Frameworks & Drivers layer.
Clean Architecture in practice
Figure 5 almost leaves the reader with more questions than answers since it's incomplete at best. This section delves deeper into the details to answer some of these. At the end a holistic overview is given including everything in one diagram.
The Controller object
The first is the Controller object. It doesn't feel quite right the way it's been illustrated for two reasons. How can the Frameworks & Drivers layer part, that depend on the Controller object, be tested in isolation, i.e. without the Controller? The second reason is that there's no way for the Frameworks & Drivers layer to pass on any data to the Controller.
To fix the first problem an interface has to be introduced in the Interface Adapters layer. This interface should then be implemented by the Controller object. See the image below.
 |
| Figure 6. Making the Frameworks & Drivers layer testable, part 1 |
To mend the second problem of passing data, a DTO has to be introduced in the Interface Adapters Layer. Please see the following figure.
 |
| Figure 7. Making the Frameworks & Drivers layer testable, part 2 |
When compared with the previous section "How to call code in a different layer without dependencies", it's easy to see that the solution above is the same as the one presented in that section i.e. one interface and one DTO. The difference however, is that in that section the flow of control is inverted compared to the source code dependencies.
The Database Gateway Implementation
A correct implementation is not as simple as presented in Figure 5 i.e. a gateway interface and its implementation. There's more to it, which the below image demonstrates.
 |
Figure 8. Clean persistence design
|
An interactor (not included in Figure 8) invokes the Database Gateway interface in the use case layer using an Entities object (not included either in Figure 8) as input argument. This is followed by the Database Gateway Implementation in the Interface Adapters layer mapping the Entities object to the DTO object, which includes translating any currency or date time fields to a format suitable for persisting in the database. The Data Mapper contains the code with the database-specific query language such as SQL and handles the persisting to and retrievals from the database. In this example the Data Mapper is the implementation of the Database Gateway interface in the Interface Adapters layer.
The Presenter and View objects
In many of the implementations that can be found online there are source code dependencies from either the Controller (in the Interface Adapters layer) to the Presenter or from the latter to the View. Those are not Clean Architecture implementations. In Figure 5 it's obvious that the View should be unaware of both the Controller and Presenter and vice versa.
When the Controller is aware of the Presenter i.e. has a "has-a" relationship to the Presenter, there's a different flow of control compared to a strict Clean Architecture implementation. The following list describes the flow of control:
- The Controller calls the Interactor through the Input Boundary interface
- The Interactor returns a Response Model
- The Controller calls the Presenter using the Response Model as input
The main disadvantage of this is that the Controller breaks the SRP (Single Responsibility Principle) due to an increase in responsibility, instead of just converting the input from the Frameworks & Drivers layer to a format suitable for the use case layer. In such a design the Output Boundary interface has also moved to the Interface Adapters layer, since the Controller would be the one to call the Output Boundary i.e. the Presenter. I'm going to stop here, since it's obvious this is not the way Clean Architecture is supposed to be implemented. This practice should be avoided since it's not strict Clean Architecture.
Now for the second incorrect way of implementing Clean Architecture, when the Presenter is aware of the View. The only reason why someone would introduce a "has-a" relationship to the View is to call the View with the View Model as argument, from the Presenter.
This breaks the Dependency Rule because it would mean that the Presenter would have a source-code dependency to the Frameworks & Drivers layer, due to the fact that the View belongs to the latter. This would also further complicate testing of the Presenter, since a new View interface would have to be introduced so that the View could be mocked. For this reason it's best to avoid this practice. Related to this, is the idea, presented in the book "Clean Architecture: A Craftsman's Guide to Software Structure and Design", by Robert C. Martin, that the View shouldn't have a need to be tested. It should be that simple that it could be considered negligible. This concept is called the Humble pattern in that book.
Flow of control in a strict Clean Architecture implementation
In my opinion, a strict Clean Architecture implementation has a flow of control that would look like the following:
- An object A (such as a framework controller) in the Frameworks & Drivers layer call the Controller in the Interface Adapters layer and passes a DTO in the latter layer.
- This DTO would be converted by the Controller to the Request Model with which the Input Boundary would be called.
- The Interactor implementing that interface would perform the dance with the entities in the Entities layer and put together a Response Model which it would call the Output Boundary interface with.
- The Output Boundary interface is implemented by the Presenter which would convert the Response Model to a View Model which would be stored in memory as a member belonging to the Presenter class instance.
- After object A's call to the Controller returns and returns nothing. It would then call the getViewModel() method on the Presenter and store the ViewModel in a local variable.
- Object A would then call the View using the local variable referencing the View Model. The View would then return either the output in a primitive format such as a String (might be a word, sentence, HTML, JSON, XML, whatever) or another DTO defined in the Frameworks & Drivers layer, which a Framework such as Spring could convert to the final output in JSON, HTML or whatever.
Please note that the Controller, Interactor and Presenter returns void i.e. nothing. The only object which returns something is the View. The Presenter produces a View Model stored in memory as its member which requires either the member to be "public" in a language like Java, or that the Presenter offers a getter for it.
Clean Architecture's dark side
Clean Architecture definitely has up-sides, but they also come at a cost. The main concern is that Clean Architecture slows down development. The primary reason for this is the amount of classes and interfaces that need to be created and maintained. To give an example of this, let's say an Interactor object wants to persist an Entity object to a database and that it's a Java Spring Boot application using Spring JPA + Hibernate. The following lists the classes and interfaces required to achieve this.
- 1 x interface (Database Gateway) in the use case layer
- 2 x classes (Database Gateway implementation + DTO) in Interface Adapters layer
- 1 x interface (Database Gateway) in the Interface Adapters layer
- 2 x classes (Database Gateway implementation + Hibernate Entity class) in the Frameworks & Drivers layer
- 1 x interface (Spring JPA repository) in Frameworks & Drivers layer
The total number of interfaces is 3, whereas the total number of classes is 4. That's a total of 7 objects.
Another example is the minimum number of classes and interfaces for each Interactor object.
- 2 x interfaces (Input/Output Boundary) in the use case layer
- 3 x classes (Interactor, Request/Response Model) in the use case layer
- 2 x interfaces (Controller and Presenter) in the Interface Adapters layer
- 4 x classes (Controller implementation, Controller DTO, Presenter and View Model) in the Interface Adapters layer
- 1 x interface (View) in the Frameworks & Drivers layer
- 2 x classes (View and View Result) in the Frameworks & Drivers layer
The total number of interfaces is 5, whereas the total number of classes is 9. That's a total of 14 objects.
The complete picture
It's always a challenge to put bits and pieces of information together. For this reason the below image was created, so you don't have to. The dotted blue arrow represents the flow of control which both starts and ends in the Framework Controller, where the arrowhead signifies the end.
Figure 9. Complete implementation
The Controller, Presenter and View interfaces are needed so that the Framework Controller can be tested independently. There is an alternative to these though. By introducing an abstraction in the form of the Facade pattern, it's possible to remove the Framework Controller's dependencies and hide them in the facade. Thus making the Framework Controller easier to test. With regards to testing, due to the intent, purpose and implementation simplicity of the facade, it wouldn't be that interesting to test. This would make the Controller, Presenter and View interfaces redundant.
 |
Figure 10. A facade to simplify the Clean implementation
|
Please note that objects such as DTOs are not included in the above figure. The facade would have only one method. Its single argument would be the Controller DTO and its output would be the finished View Result. Both the Facade interface and its implementation are part of the Frameworks & Drivers layer.
Deployment and maintenance considerations
Deployment and maintenance are two considerations that affect the
total cost of ownership of an application. Software architecture is one parameter that can greatly affect this cost. Given a lack of or confusing software architecture, an application can over time require a lot of human resources just to analyse where a new feature should be added, not to mention how to mend bugs without introducing new adverse effects.
The architecture of an application also affects the cost of deployment. For example, an application composed of micro-services can soon become unwieldy to deploy, due to the number of services, which requires automation to mitigate.
Clean architecture doesn't have the perfect solution which will provide the lowest possible TCO, but on some level it provides a structured way of organising code which paves the way for a more managed maintenance cost. With regards to deployment, Clean Architecture doesn't impose a certain mould, instead it's left to the architects to analyse and draw their own conclusions concerning the needs of their own applications.
Below I've summarised examples of how application code can be organised. Please note that the distinguishing characteristic making them cleanly architected is the four distinct layers mentioned in the previous section.
The monolith
The monolith in this article refers to an application which source code compiles to one and the same executable component as can be seen in the figure below.
By component is meant files such as .jar files in Java and .dll files in .NET.
The more people working on the same application the likelier it's for merging conflicts when using a version-control tool. Thus monoliths are suitable for applications with few simultaneous developers. In many cases the monolith is a good starting point, but extra care should be taken to ensure it's designed in a way that it's prepared to be separated into components and processes, in addition to being flexible enough so that details easily can be changed, such as whether it's a console, web or mobile application. This is one of the strengths with Clean Architecture i.e. the details are cleanly separated from the business rules of an application.
 |
| Figure 11. The monolith |
With regards to deployment, any little code change will require the whole application to be re-compiled and re-deployed. There are many cases where changes need to be made even when none of the business rules have changed. One such example is when a security vulnerability has been discovered in the current version of a framework used by the application. This would result in the whole application having to be re-compiled and deployed after updating the code with the newer version of the framework containing the fix.
Components by layer
As you've no doubt already realised there's no silver bullet in software architecture. Below I've visualised another way of organising source code, namely the "grouping components by layer" method. The Entities component houses the whole Entities layer, likewise, the Use case component contains all classes belonging to the use case layer etc.
Figure 12. Components by layer
One of the advantages is that it's possible for different teams to be assigned to different components, reducing the risk of conflicts when developing. Another is that e.g. changes in the Frameworks & Drivers layer can be deployed without affecting the rest of the application, since none of the other layers have any source code dependencies to it. Such a change could be upgrading from Spring framework 4 to 5. As long as the new version of the Frameworks & Drivers layer still complies with the Interface Adapters layer's interface, the application will continue working as before. No need to test the component containing the Interface Adapters layer nor the one containing the Entities and Use case layers.
Components by vertical slicing
The previous examples have focused on segmenting the source code into components by layer. Another option is to separate the application into components each containing the four layers as shown in the following figure. Each component would then be the home to one or more use cases. This would make the application prepared for a micro-services architecture since in effect its code would already be organised in a similar way.
 |
| Figure 13. Vertical slicing of an application |
Given an application implemented by means of vertical slicing, a framework upgrade would result in a higher deployment cost compared to both the monolith and the components by layer implementation, since each component would have to be upgraded individually. On the other hand, maybe not all components are using the same framework which would simplify things, but then again, maybe not. Then you also have to keep track of which components use what, which means more documentation and spending time maintaining it, which boils down to an increase in maintenance cost as well.
On the other hand, if the need for a change to a specific use case arrises, then in the best case scenario only one component (out of many) would have to be updated and re-deployed, which would be an improvement to the deployment aspect of the application compared to the above two ways of organising code. In a micro-services scenario this would mean that only a specific service would have to be upgraded, re-deployed and restarted while the rest of the services would be able to remain untouched.
References
- Clean Architecture: A Craftsman's Guide to Software Structure and Design by Robert C. Martin
%3CmxGraphModel%3E%3Croot%3E%3CmxCell%20id%3D%220%22%2F%3E%3CmxCell%20id%3D%221%22%20parent%3D%220%22%2F%3E%3CmxCell%20id%3D%222%22%20value%3D%22Component%203%22%20style%3D%22shape%3Dmodule%3Balign%3Dleft%3BspacingLeft%3D20%3Balign%3Dcenter%3BverticalAlign%3Dtop%3BstrokeColor%3D%23000000%3BstrokeWidth%3D1%3BfontSize%3D12%3B%22%20vertex%3D%221%22%20parent%3D%221%22%3E%3CmxGeometry%20x%3D%22480%22%20y%3D%22490%22%20width%3D%22100%22%20height%3D%22290%22%20as%3D%22geometry%22%2F%3E%3C%2FmxCell%3E%3C%2Froot%3E%3C%2FmxGraphModel%3














I think the Controller is in fact the same thing as a framework controller.
ReplyDeleteThe idea that interface adapters form their own layer is misleading in my opinion, and so is the typical diagram where it looks like its own layer. The whole point in an adapter is that it translates between two separate interfaces, therefore it has to know about, and be coupled to, them both. The controller translates between how the framework wants to pass you incoming HTTP requests, and how the application Interactors expect to receive requests -- as simple DTOs. The reason for doing so is to decouple the business logic from the framework, making it more testable and easier to understand via the single responsibility principle. All you have to do to achieve this is pull the business logic out into an Interactor and call it from the framework controller -- no need for yet another controller (and another layer), which really wouldn't serve any purpose. In your flow of control section you say the framework controller passes a DTO to the interface adapters Controller. That DTO is exactly the same as a Request Model. There's no need for another layer simply passing it along.
First of all, thank you for the comment!
DeleteIf you're right that the Controller in fact is a framework controller, then that could mean one of two things. Either an architecture to be considered "Clean" would always have to be a Model-View-ViewModel-Controller-Presenter (MVVCP) or its only "Clean" constituents would have to be the Interactor, Response/Request Model, Output Boundary Interface, Entities and Gateways. The rest would be up to the implementer to decide e.g. MVC instead of MVVCP.
I don't believe Clean Architecture would ever force you to have a MVVCP sub-architecture because it'd limit your implementation choices e.g. framework A, B use MVVCP, but not framework C which only supports MVC. So that rules that option out, at least for me. Nor do I believe the latter option to be true either since I've read the book that I refer to in the article and the Controller, Presenter, ViewModel and View are all presented as part of the architecture.
And another thing, consider a real implementation of what you're suggesting. Let's say we have a web server application where you're using a web framework that uses controllers as HTTP handlers. You then have a method belonging to a controller that gets invoked when a web request comes in. The controller adapts the HTTP data to a Request Model and calls the Interactor. Given that the relationships between the Controller, Presenter and View Model are like in Figure 5 in the article, how are we supposed to get a response back to the user that made the HTTP request? Since the controller doesn't have any knowledge of neither the Presenter nor the ViewModel.
The only solution I've found to this problem is that the framework controller cannot be the Clean Controller, but I'm hoping by writing the article that I either spread useful information to other people or that someone shows me how the architecture really is supposed to be.
Thanks for the article
ReplyDeleteStill I'm puzzled why do we need 2 separate controllers. If we have Spring mvc, for example, we could just inject JsonPresenterFactory to the @Controller. From factory we would then get new presenter instance per httprequest, and pass that as a parameter to the interactor method. Interactor would then call appropriative method of the presenter with response it produced. Presenter would just store that in memory and later on we would pop it out and transform it to json
Am I missing something here? Of course it we would have some other client (CLI,swing..)then we would need to duplicate some of the code from the @Controller (except now we would have CLIPresenter etc)
Sorry for my late response. To be fair I must admit I haven't had that much time to think about your question, but I'll try my best to answer it.
DeleteIn your alternative, the @Controller would have a "has a"-relationship to the JsonPresenterFactory, which would allow the @Controller to instantiate a presenter without having a direct dependency (a "has a"-relationship) to the presenter or its interface definition. However, this article is about a strict interpretation of Clean Architecture and to have a dependency to a maker of a thing instead of a direct dependency to the thing it creates feels a little like the same thing to me.
That said, the problem is Figure 5, which clearly shows the @Controller being void of any "has a"-relationships with the presenter or its interface type. This is why this article argues that yet another abstraction layer has to be introduced, meaning, yet another controller which invokes the @Controller and which later on invokes the presenter method.
In my opinion, implementing a solution with two controllers and all the bells and whistles that are described in this article, is in most cases not the best way to go. It all depends on the problem you're trying to solve and how you want to solve it. I think Robert C. Martin made an important point when he pointed out the essence of the Clean Architecture, which to him is the Separation of Concerns principle and the Dependency rule. The number of layers you choose in your solution is up to you. So are the objects you choose to include in your solution such as the controller, interactor etc.
In my follow-up article on this topic I conclude that Clean Architecture is not a natural fit for microservices, due to them being small and less in need of a rich architecture that allows for maintainable, testable and flexible code.
To me, I think the most useful knowledge from Clean Architecture which I carry with me in my tool belt at all times, are the two cornerstones of Clean Architecture that I wrote about two paragraphs up. That said, don't get too concerned with the number of layers, how you split a code base into containers and which objects are in that solution, because there's no one-size fits all, no silver bullet, no generic template which'll be the most optimal in all situations.
good content, sorry, I have a question, can I apply clean architecture to create an api rest, true and what would be the variant?
ReplyDelete